
レセプトデータも、もちろんデータですので機械学習に用いることができます。ただ、機械学習することを目的としてデータを分析すると、興味深いけれども活用する機会があまりないアルゴリズムができてしまいます。しかし、なんらかの課題を解決しようとして必要にせまられて機械学習を用いた場合には、実際に活用できるサービスができます。本コラムを通して、そのようなJMDCの実例をご紹介できればと思います。
杉田:JMDCのCOOの杉田と申します。今回は「機械学習とレセプトと」というテーマで、レセプトに機械学習を使うと何ができるのか、実例を交えつつ、将来的な可能性も含めてご紹介できればと思います。
穴吹:製薬本部マネージャーの穴吹と申します。毎回ですが、本記事では私がインタビュワーとなって、進めていきたいと思います。よろしくお願いいたします。機械学習とレセプトデータというところで、JMDC内では昔から「ヘルスウェザー」というサービスがあったと思いますが、まずはそのあたりからご紹介いただけますでしょうか。
杉田:「ヘルスウェザー」は、JMDCの持つレセプトデータと日本気象協会の持つ気象データを掛け合わせて、気象条件に基づいて、喘息や片頭痛などの発作が起こるリスクを予測するサービスです。
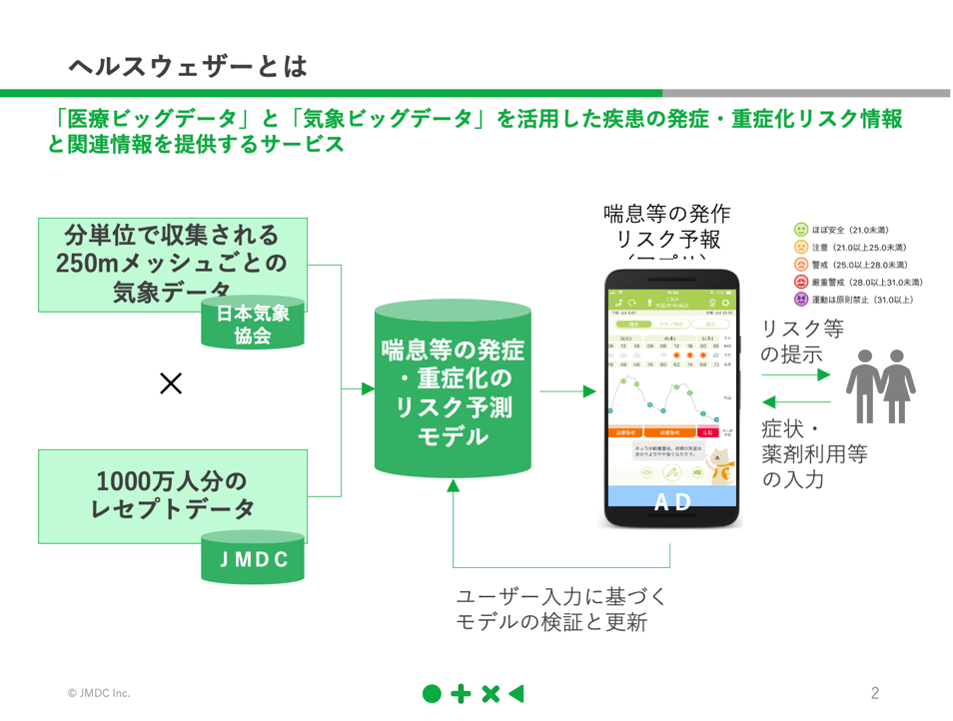
それを一般ユーザー向けにアプリで展開していて、そのアプリを活用することで現在地の天気予報から、今後数日にわたって症状が重症化するリスクがわかり、事前に対処ができるというものになります。
―非常におもしろいですよね。特に公開している喘息に関しては、ユーザーがアプリリリース後2年近くたっても変わらず伸び続けていると聞いています。
杉田:そうですね、やはり持病として片頭痛や喘息といった病気を抱える方にとっては、普段から天気は気になる情報でしょうし、それと同時にリスクが見えるとよりよいということかと思います。機械学習をどう用いているかというと、過去データを学習材料として、気象データとしては、気温や気圧の値はもちろん、その変化の大きさや降水量、日内変動を用い、レセプトデータとしては日々の患者数や処方薬のボリュームなどを用いて、アルゴリズムを構築しています。そこに、最新の気象データをインプットすることで、リスク予報を出しているのです。
例えば片頭痛ですと、気圧が下がると頭が痛くなる、というようなイメージもあるのですが、機械学習してみると、急激な気温の低下の方が要素としては影響が大きかったりと、興味深い結果が得られたりします。
―なるほど、おもしろいですね。それで少しでも発作を未然に防ぐことができる患者さんが増えればよいですね。そして製薬企業も最近は医薬品以外で患者さんのためにできることを模索されている印象なので、そう言った場面でも活用いただけるものかと思います。
杉田:ヘルスウェザーは気象データとレセプトデータの掛け合わせによる機械学習でしたが、レセプトデータ単独の実例もあります。最近希少疾患関連の分析のご依頼をいただくことが増えてきましたが、その中で、未診断の潜在患者にどうアプローチすればよいか、というお話もいくつかいただいております。希少疾患の確定診断がついている患者はもちろん少ないので、その中で薬剤のシェアを伸ばすというよりも、確定診断がついた患者をどう増やすか、という発想だと思います。その中で、施策の一つとしてレセプトデータと機械学習を使えば、スクリーニングサポートや患者啓発が可能だと思っています。
―確かに通常のレセプト分析でも、希少疾患患者が地域ごとにどれだけいるかや、ペイシェントジャーニーとして診断までにどのような受診行動をしていてどの程度の期間がかかっているか、みたいというご依頼は増えてきてますね。
杉田:そうですね、それも診断までにすごい時間がかかっているのではないか、未診断の潜在患者が多いのではないか、という仮説だと思います。試しに、社内での研究として、希少疾患200疾患ぐらいに関して、文献にて言われている推定患者数と、弊社1000万人データベースから試算される確定診断がついた患者数を比較してみました。そうすると、確定診断患者数が文献の患者数よりも少ない疾患はいくつかあり、その中でも結節性硬化症という疾患を題材に、疑いのリスクを判定するアルゴリズムを構築してみました。
―なぜ結節性硬化症という疾患に注目したのですか。
杉田:一つには、文献では日本に1.5万人程度患者数が存在するといわれている一方で、レセプトデータからは確定診断患者が4,000人程度と試算され、未診断の患者が多いのではと思われたことと、もう一つは多様な臓器に過誤腫/過誤組織ができる疾患であるため多様な症状を示し、患者さんが皮膚科や神経内科など様々な診療科を受診するため、情報が一元化されず診断が難しいのではと思われたことがあります。
そして結節性硬化症の確定診断のついた患者のレセプトデータを正解データとして、機械学習させ、その診断に対して、どの要素がどれだけ影響したかをみたのが下の図になります。
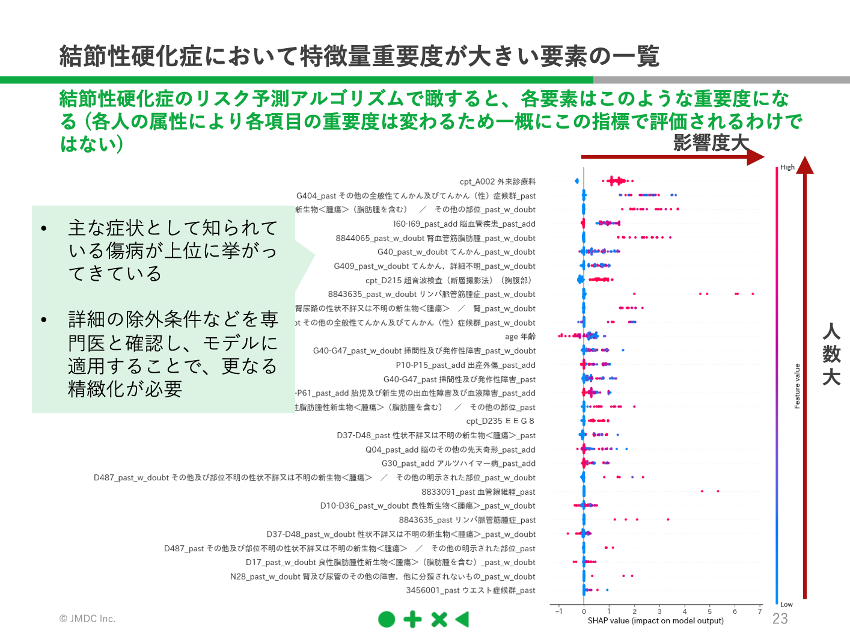
―こちらの図はどのようにみたらいいのでしょうか?
杉田:詳細は省きますが、上に行くほど多くの人に大きな影響を及ぼした重要度の高い項目で、赤や青の点の位置は個々の患者の診断に対してどの程度の影響を及ぼしたかを示しています。項目名をみていただくと、「てんかん」や「腎血管筋脂肪腫」、といった、結節性硬化症に関連の深い項目が、比較的上の方に来ていることがわかります。
―確かに疾患の特徴がでてきていますね。このアルゴリズムは先ほどのヘルスウェザーのアプリのように、実際にはどのように活用できるのでしょうか。
杉田:活用方法としてはいくつか考えられます。一つには、医師や患者向けのチェックシートとしての活用が考えられます。この症状があると、xx点、この症状があるとxx 点というようなチェックリストを作り、点数が高い場合にその疾患である疑いが強まる、という形です。医師も必ずしもその疾患の専門家ではないですし、チェックシートがあればその疾患を気にするきっかけにもなります。もちろんレセプトデータは保険病名であらゆる症状が記載されているわけではないので、チェックシートを作るためには、アルゴリズムをベースとして、KOLなどとの議論や精緻化が必要ですが、機械学習がスコア化の役に立ちます。
また、他の活用方法としては、レセプトデータを持つシステムにアルゴリズムを組み込み、自動でアラートが立つようにするということも考えられます。
例えばJMDCのサービスで、連携している健保加入者の方々に使っていただいている「PepUp」というアプリは、レセプトデータと連携しているので、そのようなアルゴリズムを組み込めば自動でアラートをだすことができます。
―なるほど、そのように実装をすれば、未診断の患者さんの診断がつく可能性があがるということですね。他にも機械学習を用いることでできることなどあるのでしょうか。
杉田:そうですね、JMDCには健康診断のデータも蓄積されていますので、それとレセプトデータを掛け合わせることで、生活習慣病の重症化リスクのモデルを構築しています。
最近、NASHというような新しい疾患概念がでてきていますが、生活習慣病同様に、肝臓の繊維化の度合いを予測するモデルなどもできますので、それらを用いると患者さんの啓発とともに、発症予防ができると思います。同様に他のデータと掛け合わせることで、この領域はいくらでも価値を広げることができると思っています。
-有難うございます。それでは今回もこのあたりで終了とさせていただければと思います。
▷記事提供元は こちら (JMDC REAL WORLD)
 【コラム】JMDC COOに聞く!RWDによる治験2.0
【コラム】JMDC COOに聞く!RWDによる治験2.0










.png%3Ffm%3Dwebp&w=640&q=75)



