
近年、医療AIの成果を報告するニュースが増えてきました。 そのニュースの中で「感度は〇%でした」「AUC=〇が確認された」などと記載されることがあります。このような数値を見た際、結果の良し悪しを瞬時に理解できるでしょうか。医療・製薬業界のDX事例の読み解き方を、デジタルが苦手な方にも分かりやすく解説する本シリーズ。第3回目は「医療AIの良し悪しを見る3つのポイント」を紹介します。
医療AIの良し悪しを見極める3つのポイント
AIを活用した医療機器(医療AI)が、厚労省や米国食品医薬品局(FDA)に承認される事例が増えています(シリーズ
第2回参照
)。例えば、内視鏡画像から早期胃がんの診断を支援するAIや、乳がんの病理検体画像からホルモン受容体(ER/PR)とHER2のステータスを診断するAIなどがあります。
最近の医療AIのほとんどは、「胃がんか、正常か」や「HER2陽性か、陰性か」など、「1」か「0」か(2値分類)のように、「分類」をするAIと言えます。
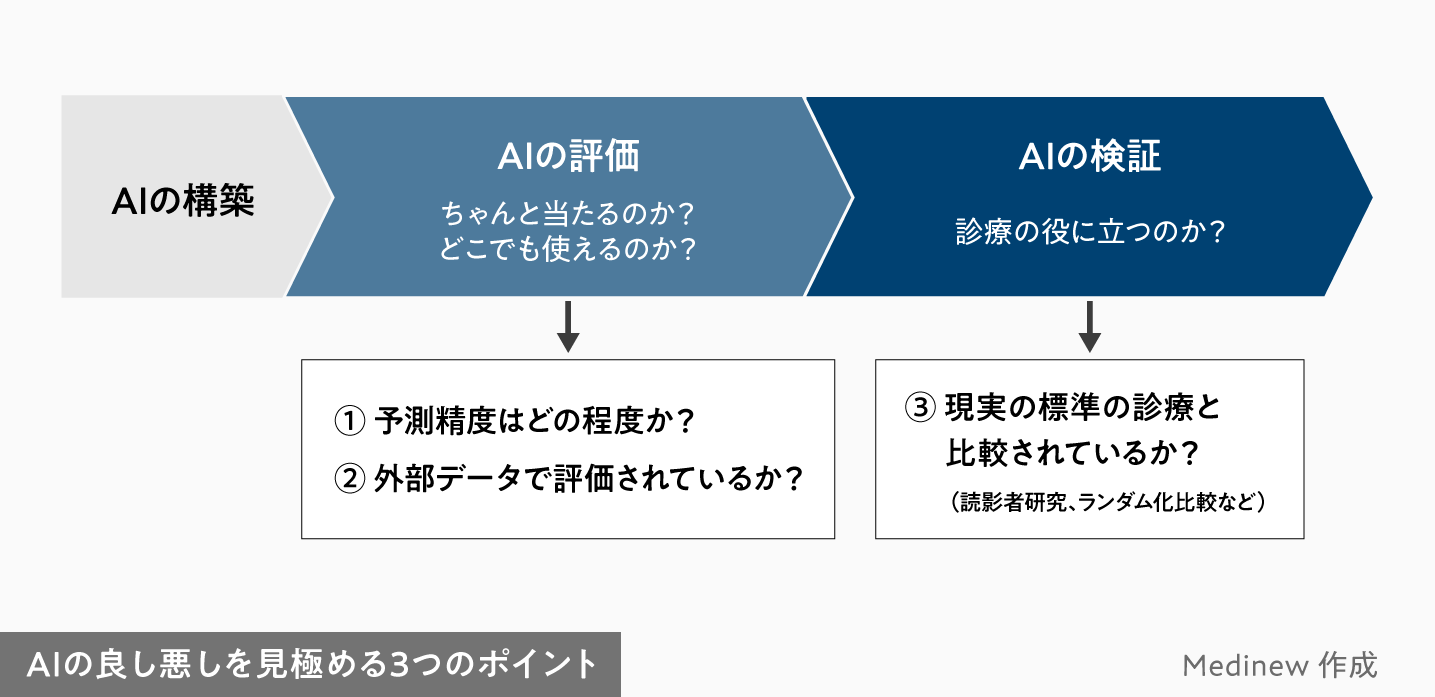
このような分類をする医療AIの良し悪しを見極めるポイントは3つあります。
ちゃんと当たるのか、どこでも使えるのか、実際の診療に役に立つのか、の3点です。
具体的にいえば、①予測精度(感度、陽性的中率、AUCなど)はどの程度か、②その評価結果は外部データが使われているのか、③現実の標準の診療と比較されているのか、ということです。
なぜこの3つのポイントが重要なのか。本記事では、2021年8月に医療機器製造販売承認申請された胃がん鑑別AI
1)
を例に3つのポイントについて解説します。
①予測精度はどの程度か?
多くの医療AIの良し悪しを見極める1つ目のポイントとして「ちゃんと当たっているか?」という観点は当然ながら重要です。言い換えると「分類の予測精度はどの程度か?」を理解することです。分類の予測精度を表す際には、感度や特異度、陽性的中率、陰性的中率という指標がよく用いられます。
感度/陽性的中率とは
上記の胃がん鑑別AIの論文のResultには「感度92.2%」と記載があります 2) 。感度は、カバー率だとイメージすると分かりやすいでしょう。感度が高ければ、見落としが少ないと解釈できます。
感度を算出する際に、多くの場合まず「混同行列」が作成されます。行列と聞くと難しい数学をイメージしがちですが、それほど難しいものではありません。実際の「+」か「-」かという結果と、AIが出した予測の「+」か「-」かという結果を突き合わせて表にしたものです。
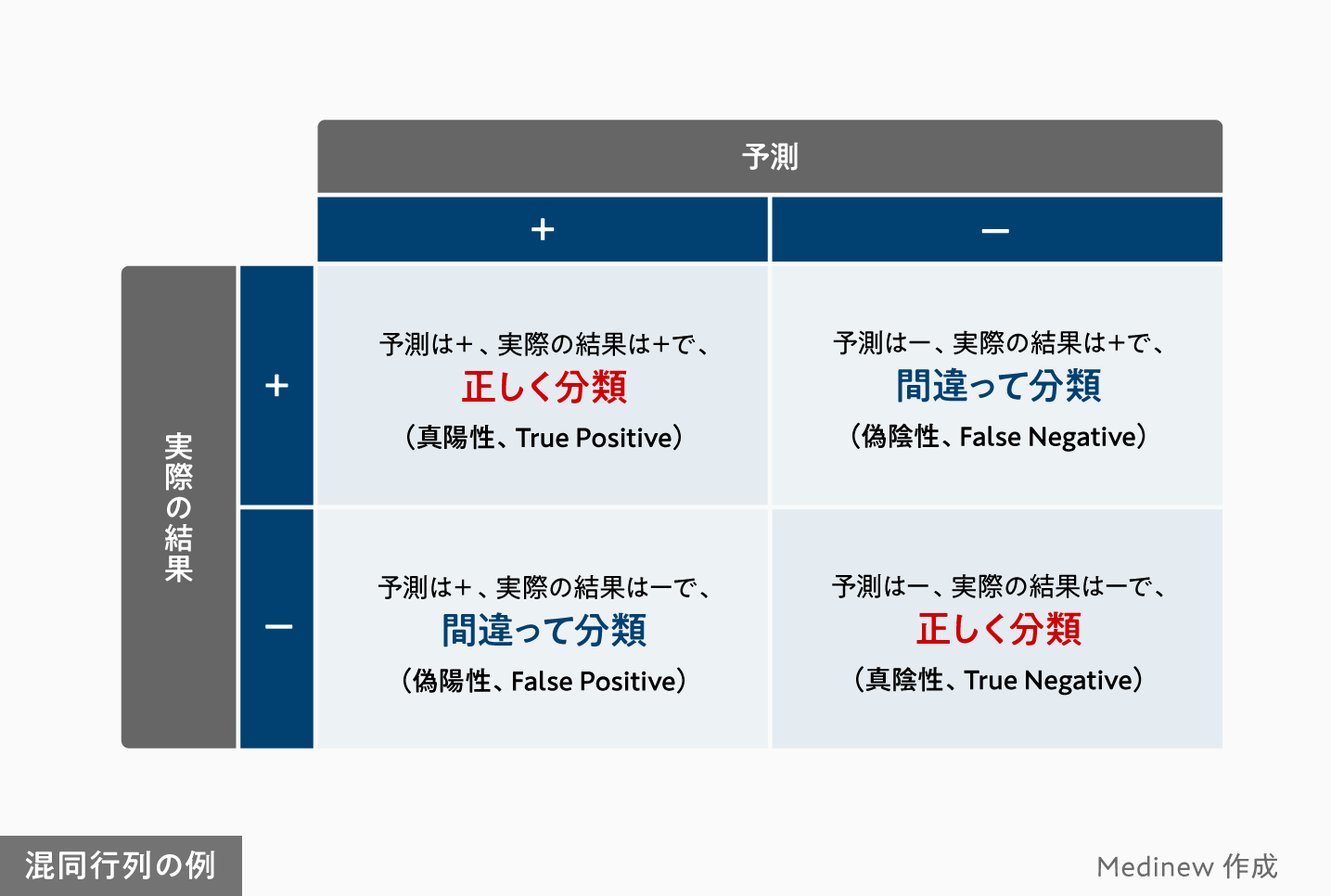
では、胃がん鑑別AIの予測では、どのくらい実際の胃がんをカバーできているのでしょうか。この事例では、実際に「胃がん」か「正常」かという結果と、胃がん鑑別AIが出した「胃がん」か「正常」かという結果と突き合わせると以下の表のようになります。

この場合の感度は、71(胃がん鑑別AIが胃がんと予測した数)/77(実際の胃がんの病変数)=92.2%です。胃がん鑑別AIは実際の胃がんの見落としは少なさそうな結果と解釈できます。
予測精度の別の観点として、胃がん鑑別AIの予測は、どのくらい当たっているのか?という点も重要です。
いくら見落としが少なく(感度が高く)ても、間違えてばかりではオオカミ少年のようです。つまり、見落としも、間違いも少ないことが、「予測精度が高い」といえます。
胃がん鑑別AIが胃がんと分類した場合、実際にはどのくらい胃がんだったのかを計算します。これを「陽性的中率」と言います。

この場合の陽性的中率は、71(胃がん鑑別AIが胃がんと予測した中の実際の胃がんの数)/232(胃がん鑑別AIが胃がんと予測した数)=30.6%です。陽性的中率から、胃がん鑑別AIは胃がんでない病変も多めに胃がんと分類していると解釈できます。
AUCとは
感度や陽性的中率により、見落としや間違いの度合いの判断が可能です。
そのほか、よく出てくる予測精度の指標に「AUC」があります。実際に、胃がん鑑別AIの論文にも「AUC=0.757」と記載があります 3) 。
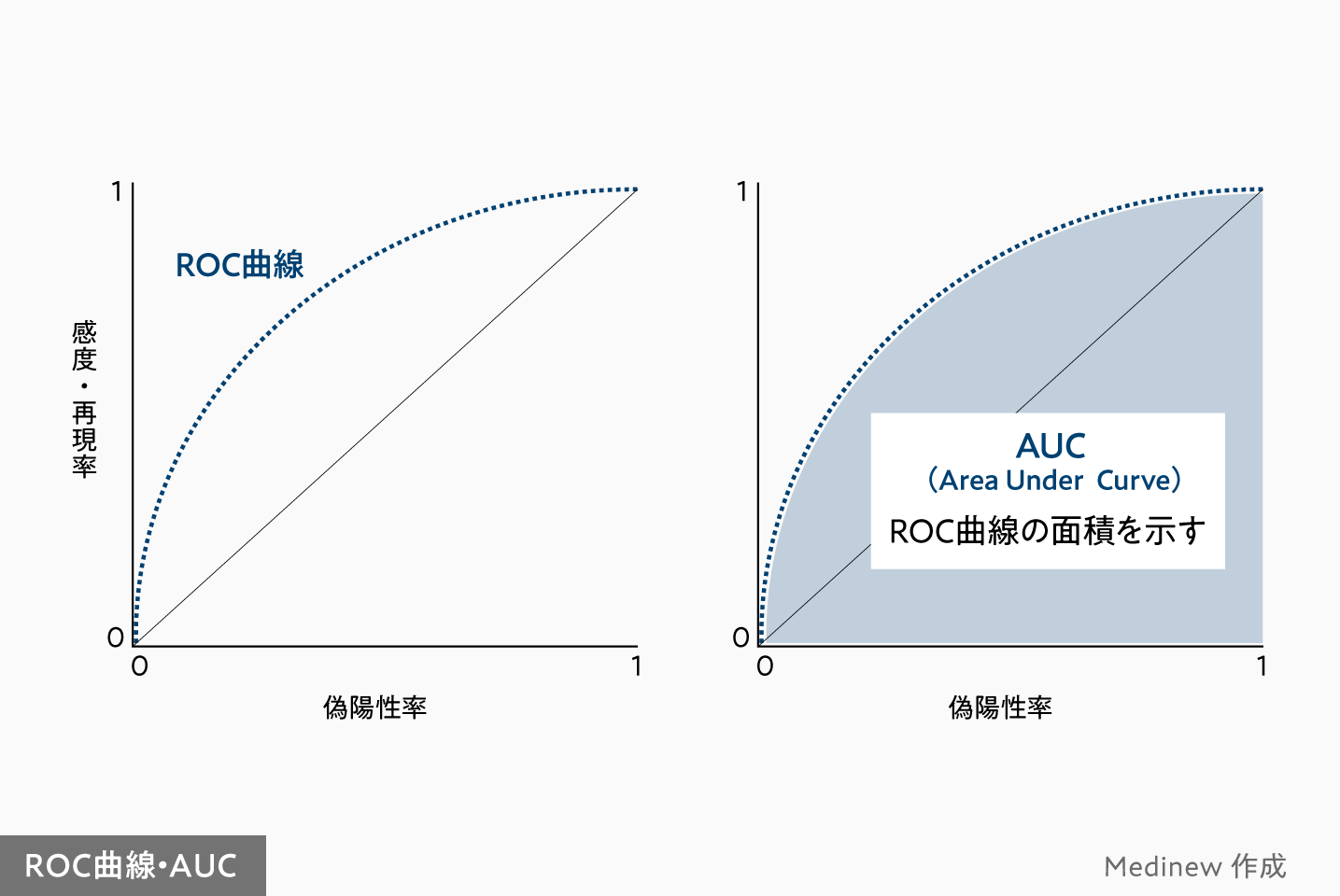
AUCのイメージは、見落としも間違いも、1つの曲線の面積で表現することです。最大値を1とし、AUCの面積が大きければ大きいほど、見落としも間違いも少ないと解釈できます。
AUCを算出するには、まず「ROC曲線」を描きます。あまりなじみのない言葉ですが、ROC曲線とは、縦軸に感度(見落としの少なさ)、横軸に偽陽性率(間違って+と分類した割合)をプロットした曲線です。
このROC曲線の面積を「AUC(Area Under Curve)」と呼びます。
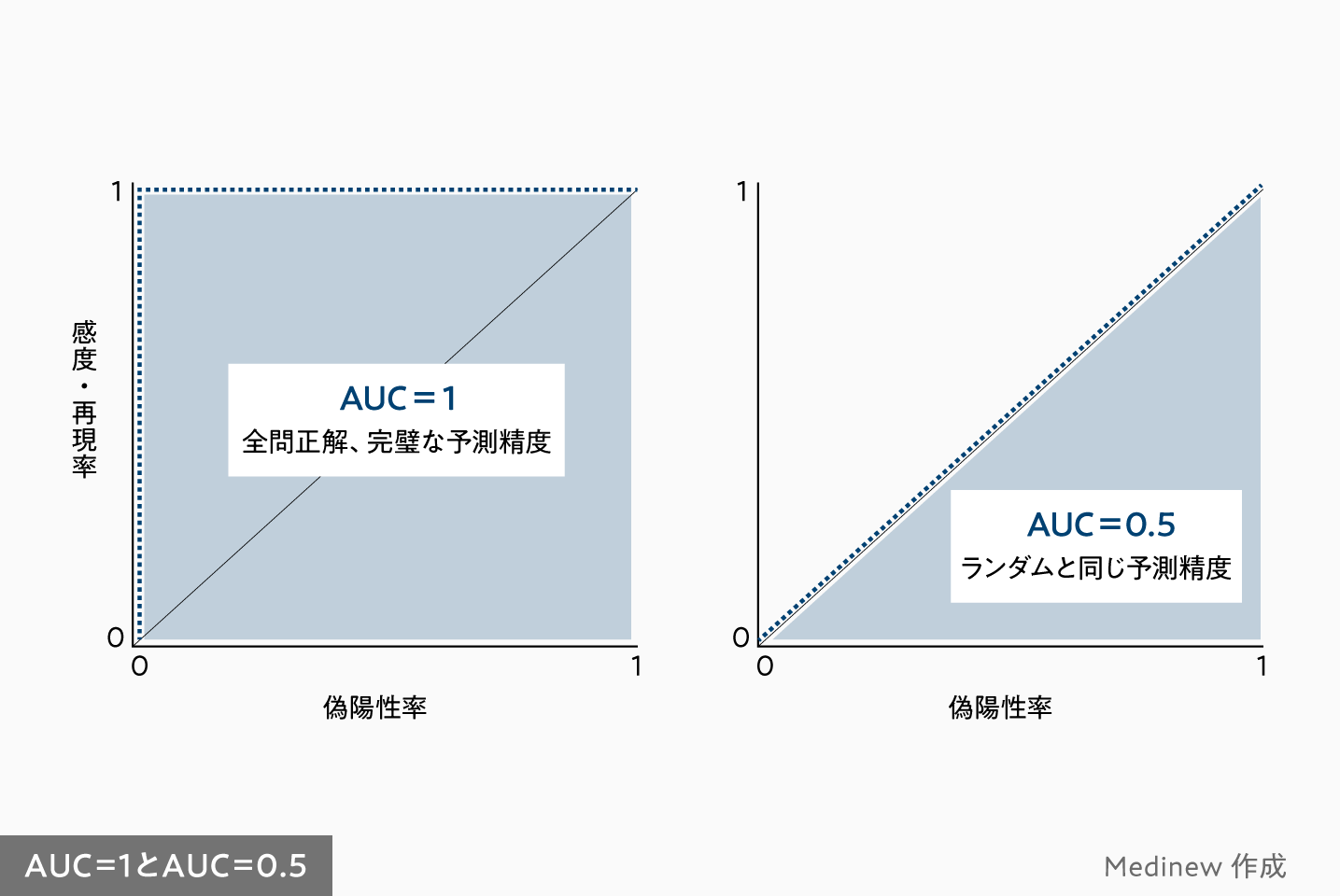
ROC曲線の面積が大きくなればなるほど、つまりAUCが1に近づけば近づくほど、見落としも間違いもない高い予測精度といえます。逆に、ROC曲線の面積が小さくなればなるほど(=AUCが0.5に近づけば近づくほど)、ランダムに予測した場合、つまりコインを投げた場合と同じ予測精度になります。
AUCが0.9を超えればかなり高精度/0.8前後は高精度/0.7未満はそんなに高精度ではない、といった程度で捉えておけばよいでしょう。
②外部データで評価されているか?
2つ目の重要なポイントは「医療AIはどこでも使えるのか?」ということです。
医療AIは、胃がん病変と正常組織の画像データを使って、こういう画像の時は胃がんで、こういう画像は正常、とデータをもとに機械学習によって構築されます。
しかし、医療AIを構築する際に起こる「過学習、過剰適合(オーバーフィッティング)」という現象が問題の1つとされています。過学習、過剰適合は「今回のデータでは良く分類できたかもしれないが、別のデータでは上手く分類できない」という現象です。
過学習しているAIのイメージは、ある問題集をひたすら丸暗記して、その問題集に載っている問題ならほぼ100点をとれるものの、本番の受験では点数が取れない、といった状態と捉えてください。今回の施設データでは良い分類ができていたが他の施設ではうまく分類できないようでは、構築された医療AIが過学習を起こしており、現実的に活用できるAIとはいえません。
そのため、構築したAIを評価する際に「外部データで評価されているのか」は重要なポイントとなります。
理想は、構築には使われてない他施設の画像等のデータを外部から独立して取得し、そのデータで感度や陽性的中率、AUCなどが分類できているAIを評価することです。全く別施設の外部データで評価し高い予測精度が確認できていれば、過学習はなく、どこでも使える医療AIと判断できます。
胃がん鑑別AIの事例では、構築に使った上部消化管内視鏡(EGD)画像データとは別に、新しいEGD画像が2296枚集められ評価されました。その評価の結果は上述の通りです。
1つ気になる点としては、胃がん鑑別AIの構築にも使われている、がん研究会有明病院の1施設から収集されたデータを使って評価をしている点です。もし胃がん鑑別AIの構築にも使われていない施設で、かつ、複数の施設から集められたデータを使って評価されていたとしたら、「どこでも使える(過学習がない)AI」とさらに判断がしやすくなると考えられます。
③現実の標準の診療と比較されているか?
3つ目のポイントは、「医療AIは診療の役に立つのか?」という点です。
もし仮に、専門医が胃がんか正常かを100%正しく分類できている状況であれば、医療AIがどれだけ正確に分類できたとしても、診断精度の向上という意味ではあまり役には立たないでしょう。ですが、専門医でも胃がんか正常かを30%しか正しく分類できない状況だとしたら、医療AIの正確さが50%であれば十分な価値があるかもしれません。
つまり、医療AIの予測精度の高い/低いだけを見ても、実臨床に役立つかは別問題ということです。そのためには、医療AIを見極めるポイントとして「現実の標準の診療と比較されているか?」という点を確認すると良いでしょう。
方法としては、読影者研究や、ランダム化比較試験などがあります。
a. 読影者研究とは
読影者研究は、評価用データを医療AIと医師それぞれで評価し、結果を比較します。
胃がん鑑別AIの事例では、診断能力を67人の内視鏡医と比較した論文が報告されています 3) 。この研究では140例、2940枚のEGD画像を評価用データとして集め、診断能力を比較・検証しました。
胃がん鑑別AIの感度は58.4%、内視鏡医67人の感度は31.9%でした。言い換えると「胃がんの見落としは胃がん鑑別AIの方が少ない」ということです。一方で、AIの陽性的中率は26.0%、内視鏡医67人の陽性的中率は46.2%でした。これは「胃がんか正常かの間違いは、内視鏡医の方が少ない」と解釈できます。
b.ランダム化比較試験とは
さらに厳密に検証するためには、多施設前向きランダム化比較試験があります。
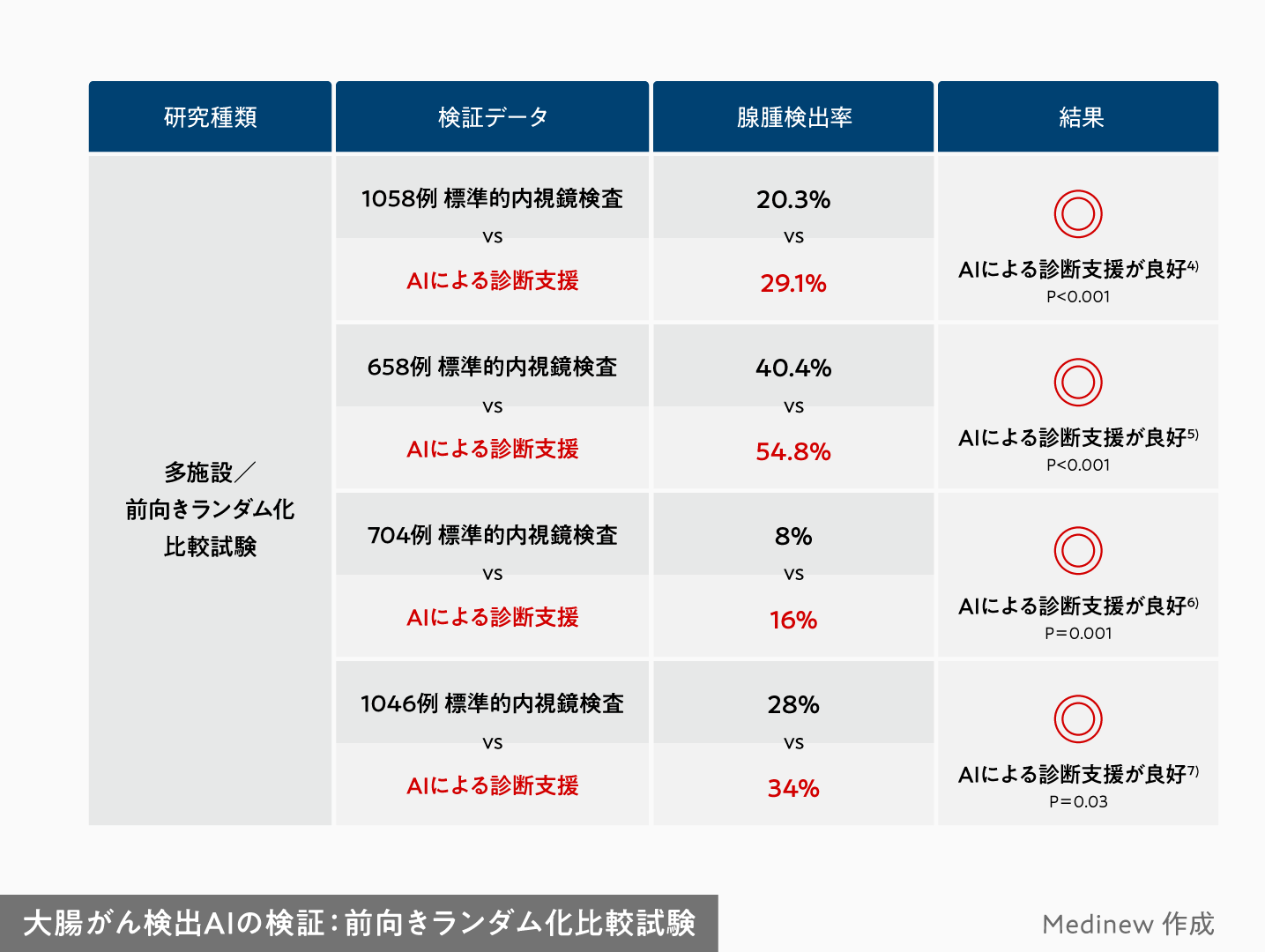
胃がん鑑別AIでは実施されていませんが、例えば大腸がん検出AIでは、複数のランダム化試験の結果が報告されています。主要評価項目である腺腫検出率において、通常の内視鏡検査よりも、大腸がん検出AIの支援による内視鏡検査の方が6%~14%高いと、有意差をもって確認されています 4)~7) 。
医療AIの評価はポイントをおさえれば容易にできる
医療AIの成果発表を目にした際にその成果を理解する大事なポイントとなるのは、本記事で紹介した以下の3つです。
- 予測精度(感度、陽性的中率、AUCなど)はどの程度か
- 外部データで評価されているか
- 現実の標準の診療と比較されているのか
実際のニュースや論文を見ていると、予測精度は良さそうでも、外部データで評価されていない報告や、実際の診療と比較されていない発表は意外と多くあります。
この3点を押さえておけば、良い医療AIなのかどうか大まかに判断することができます。これから医療AIに関連するニュースを見たら、まずは本記事で紹介した良し悪しを見極める3つのポイントを考えてみてください。
<参考>
※URL最終閲覧日2022年2月10日
1)”世界初の胃がん鑑別AIを医療機器製造販売承認申請いたしました”.AIM社.2021/08/31,
https://www.ai-ms.com/20210831/591/
2)Gastric Cancer 2018 Jul;21(4):653-660,
https://link.springer.com/article/10.1007%2Fs10120-018-0793-2
3)Digestive Endoscopy 2021 Jan;33(1):141-150.
https://onlinelibrary.wiley.com/doi/10.1111/den.13688
4)Gut 2019 Oct;68(10):1813-1819.
https://gut.bmj.com/content/68/10/1813
5)Gastroenterology 2020 Aug;159(2):512-520.e7.
https://www.gastrojournal.org/article/S0016-5085(20)30583-7/fulltext?referrer=https%3A%2F%2Fpubmed.ncbi.nlm.nih.gov%2F
6)Lancet Gastroenterol Hepatol 2020 Apr;5(4):352-361.
https://www.thelancet.com/journals/langas/article/PIIS2468-1253(19)30413-3/fulltext
7)Lancet Gastroenterol Hepatol 2020 Apr;5(4):343-351.
https://www.thelancet.com/journals/langas/article/PIIS2468-1253(19)30411-X/fulltext
 【初心者向け】医療・製薬業界DX事例の読み解き方#2:医療で活用されるAIの種類
▷
そのほかの「医療・製薬業界DX事例の読み解き方」シリーズを読む
【初心者向け】医療・製薬業界DX事例の読み解き方#2:医療で活用されるAIの種類
▷
そのほかの「医療・製薬業界DX事例の読み解き方」シリーズを読む











.png&w=640&q=75)



